Algoritmos de Clasificación y de Regresión
Existen diferencias entre los algoritmos que se deben utilizar en Machine Learning si tenemos datos etiquetados o no. Como en cualquier aspecto de la vida, la herramienta a utilizar depende del problema a resolver.
Cuando trabajamos con datos etiquetados esperamos que el algoritmo sea capaz de entregar como resultado esas mismas etiquetas frente a un nuevo dataset de entrada; lo cual es distinto a lo que resulta al trabajar con datos no etiquetados: en este último caso el resultado depende de la nueva entrada ya que lo que se busca descubrir son relaciones ocultas entre los datos y variables de un nuevo dataset.
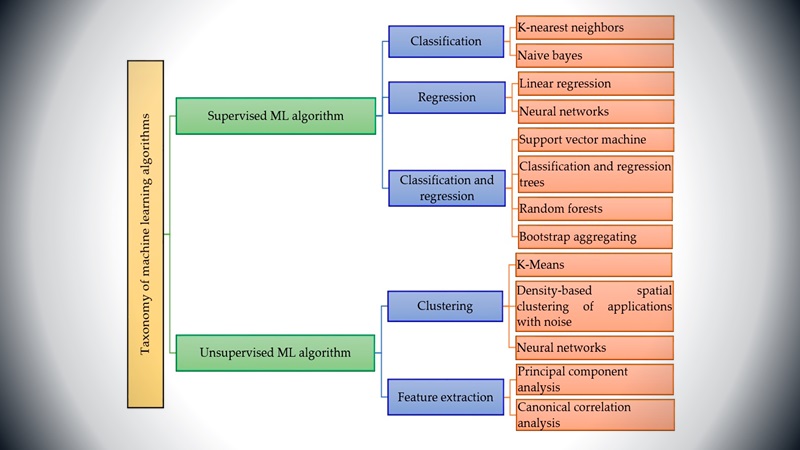
Este aspecto de "las etiquetas" es la piedra angular de la diferenciación de los dos tipos principales de algoritmos de Machine Learning: los supervisados (con etiquetas),y los no supervisados (sin etiquetas). Existe un tercer tipo, llamado "reforzados", que dependen de interacciones externas y mecanismos de recompensa.
Dentro del mundo de los algoritmos supervisados, existen dos tipos populares de métodos, correspondiente a los de clasificación y a los de regresión. Incluso existe un tercer tipo que dependiendo del problema se puede aplicar tanto para clasificación como para regresión.
Comprender las diferencias conceptuales entre ellos es útil para entender los algoritmos con que se relacionan y cómo dar uso a estas herramientas.
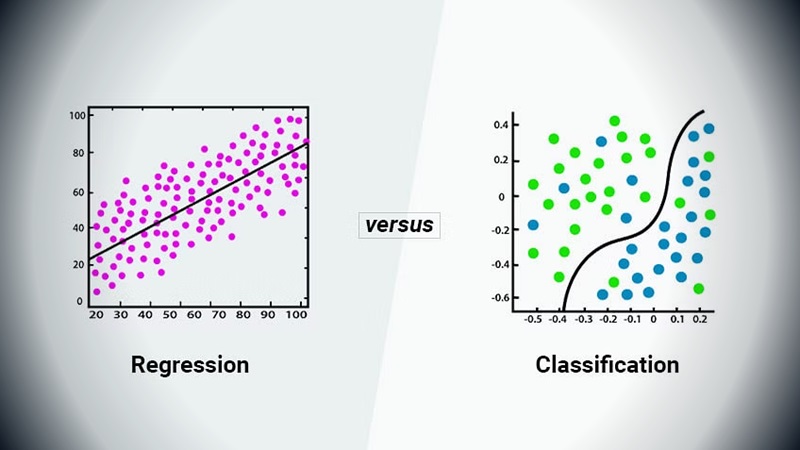
Algoritmos de Clasificación
Los algoritmos de clasificación se usan cuando el resultado deseado es una etiqueta discreta. En otras palabras, son útiles cuando la respuesta al problema cae dentro de un conjunto finito de resultados posibles.
En el caso de que el modelo entrenado sea para predecir cualquiera de las dos clases objetivos, verdadero o falso, por ejemplo, se le conoce como clasificación binaria. Algunos ejemplos de esto son: predecir si un alumno aprobará o no, predecir si un cliente comprará un producto nuevo o no.
Por su parte, si tenemos que predecir más de dos clases objetivos, se le conoce como clasificación multicategoría. Este tipo de clasificación es útil para la segmentación del cliente, la categorización de imágenes y audio, entre otras aplicaciones.
Algoritmos de Regresión
Por otro lado, la regresión es útil para predecir resultados que son continuos, eso significa que la respuesta a su pregunta se presenta mediante una cantidad que puede determinarse de manera flexible en función de las entradas del modelo en lugar de limitarse a un conjunto de etiquetas. En algunos casos, de hecho el más basico, conocido como Regresión Lineal, el valor predicho se puede usar para identificar la relación lineal entre los atributos.
La regresión lineal es el ejemplo más popular de un algoritmo de regresión. Aunque a menudo se subestima debido a su relativa simplicidad, es un método versatil que se puede usar para predecir los precios de viviendas, la probabilidad de que los clientes se desvién o los ingresos que un cliente generará.
De ella surgen variaciones como la regresión lineal múltiple, que se utiliza cuando una variable depende linealmente de varias otras; las regresiones polinómicas; exponeciales; y logarítmicas, entre otras. Finalmente, del mundo de las regresiones surgen también otros modelos, como la familia ARIMA y otras aplicaciones de las que conversaremos más adelante.
Si te gustó este artículo, también recomendamos los siguientes:



Gracias por tu visita. Y recuerda: en Blue Raptor desarrollamos una IA especializada para que todos puedan construir sus propios forecast o proyecciones de manera simple y confiable.
© 2023 Blue Raptor SpA. | Av. Apoquindo 6410, Of. 605, Las Condes | Todos los derechos reservados.